[1]:
# Install required packages.
import os
import torch
os.environ['TORCH'] = torch.__version__
print(torch.__version__)
# !pip install -q torch-scatter -f https://data.pyg.org/whl/torch-${TORCH}.html
# !pip install -q torch-sparse -f https://data.pyg.org/whl/torch-${TORCH}.html
# !pip install -q torch-cluster -f https://data.pyg.org/whl/torch-${TORCH}.html
# !pip install -q git+https://github.com/pyg-team/pytorch_geometric.git
# Helper functions for visualization.
%matplotlib inline
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
def visualize_mesh(pos, face):
fig = plt.figure()
ax = fig.gca(projection='3d')
ax.axes.xaxis.set_ticklabels([])
ax.axes.yaxis.set_ticklabels([])
ax.axes.zaxis.set_ticklabels([])
ax.plot_trisurf(pos[:, 0], pos[:, 1], pos[:, 2], triangles=data.face.t(), antialiased=False)
plt.show()
def visualize_points(pos, edge_index=None, index=None):
fig = plt.figure(figsize=(4, 4))
if edge_index is not None:
for (src, dst) in edge_index.t().tolist():
src = pos[src].tolist()
dst = pos[dst].tolist()
plt.plot([src[0], dst[0]], [src[1], dst[1]], linewidth=1, color='black')
if index is None:
plt.scatter(pos[:, 0], pos[:, 1], s=50, zorder=1000)
else:
mask = torch.zeros(pos.size(0), dtype=torch.bool)
mask[index] = True
plt.scatter(pos[~mask, 0], pos[~mask, 1], s=50, color='lightgray', zorder=1000)
plt.scatter(pos[mask, 0], pos[mask, 1], s=50, zorder=1000)
plt.axis('off')
plt.show()
1.11.0
5. Point Cloud Classification with Graph Neural Networks¶
In this tutorial, you will learn the basic tools for point cloud classification with Graph Neural Networks. Here, we are given a dataset of objects or point sets, and we want to embed those objects in such a way so that they are linearly separable given a task at hand. Specifially, the raw point cloud is used as input into a neural network and will learn to capture meaningful local structures in order to classify the entire point set.
Let’s dive in by looking at a simple toy dataset provided by PyTorch Geometric, the `GeometricShapes <https://pytorch-geometric.readthedocs.io/en/latest/modules/datasets.html#torch_geometric.datasets.GeometricShapes>`__dataset.
Data Handling¶
The GeometricShapes dataset contains 40 different 2D and 3D geometric shapes such as cubes, spheres and pyramids. There exists two different versions of each shape, and one is used for training the neural network and the other is used to evaluate its performance.
[2]:
from torch_geometric.datasets import GeometricShapes
dataset = GeometricShapes(root='data/GeometricShapes')
print(dataset)
data = dataset[0]
print(data)
visualize_mesh(data.pos, data.face)
data = dataset[4]
print(data)
visualize_mesh(data.pos, data.face)
GeometricShapes(40)
Data(pos=[32, 3], face=[3, 30], y=[1])
/home/user/anaconda3/envs/gnn/lib/python3.7/site-packages/ipykernel_launcher.py:19: MatplotlibDeprecationWarning: Calling gca() with keyword arguments was deprecated in Matplotlib 3.4. Starting two minor releases later, gca() will take no keyword arguments. The gca() function should only be used to get the current axes, or if no axes exist, create new axes with default keyword arguments. To create a new axes with non-default arguments, use plt.axes() or plt.subplot().

Data(pos=[4, 3], face=[3, 2], y=[1])

We can easily import and instantiate the GeometricShapes dataset via PyTorch Geometric, and print out some information, e.g., the description of the dataset or some information about the attributes present inside a single example. In particular, each object is represented as a mesh, holding information about the vertices in pos and the triangular connectivity of vertices in face (with shape [3, num_faces]).
Point Cloud Generation¶
Since we are interested in point cloud classification, we can transform our meshes into points via the usage of “transforms”. Here, PyTorch Geometric provides the `torch_geometric.transforms.SamplePoints <https://pytorch-geometric.readthedocs.io/en/latest/modules/transforms.html#torch_geometric.transforms.SamplePoints>`__ transformation, which will uniformly sample a fixed number of points on the mesh faces according to their face area.
We can add this transformation to the dataset by simply setting it via dataset.transform = SamplePoints(num=...). Each time an example is accessed from the dataset, the transformation procedure will get called:
[3]:
import torch
from torch_geometric.transforms import SamplePoints
torch.manual_seed(42)
# 256 of points will be sampled
# the face tensor will be removed
dataset.transform = SamplePoints(num=256)
print("There are 256 points in 3-dimension, in dataset[y]")
data = dataset[0]
print(data)
print(data.y)
visualize_points(data.pos, data.edge_index)
data = dataset[4]
print(data)
print(data.y)
visualize_points(data.pos)
There are 256 points in 3-dimension, in dataset[y]
Data(pos=[256, 3], y=[1])
tensor([0])

Data(pos=[256, 3], y=[1])
tensor([4])

[4]:
data = dataset[14]
print(data)
visualize_points(data.pos)
Data(pos=[256, 3], y=[1])

PointNet++¶
Since we now have a point cloud dataset ready to use, let’s look into how we can process it via Graph Neural Networks and the help of the PyTorch Geometric library.
Here, we will re-implement the PointNet++architecture, a pioneering work towards point cloud classification/segmentation via Graph Neural Networks.
PointNet++ processes point clouds iteratively by following a simple grouping, neighborhood aggregation and downsampling scheme:
The grouping phase constructs a graph in which nearby points are connected. Typically, this is either done via \(k\)-nearest neighbor search or via ball queries (which connects all points that are within a radius to the query point).
The neighborhood aggregation phase executes a Graph Neural Network layer that, for each point, aggregates information from its direct neighbors (given by the graph constructed in the previous phase). This allows PointNet++ to capture local context at different scales.
The downsampling phase implements a pooling scheme suitable for point clouds with potentially different sizes. We will ignore this phase for now and will come back later to it.

Phase 1: Grouping via Dynamic Graph Generation¶
PyTorch Geometric provides utilities for dynamic graph generation via its helper package `torch_cluster <https://github.com/rusty1s/pytorch_cluster>`__, in particular via the `knn_graph <https://pytorch-geometric.readthedocs.io/en/latest/modules/nn.html#torch_geometric.nn.pool.knn_graph>`__ and `radius_graph <https://pytorch-geometric.readthedocs.io/en/latest/modules/nn.html#torch_geometric.nn.pool.radius_graph>`__ functions for \(k\)-nearest neighbor and ball query graph
generation, respectively.
Let’s see the knn_graph functionality in action:
[5]:
from torch_cluster import knn_graph
data = dataset[0]
data.edge_index = knn_graph(data.pos, k=6)
print(data.edge_index.shape)
visualize_points(data.pos, edge_index=data.edge_index)
data = dataset[4]
data.edge_index = knn_graph(data.pos, k=6)
print(data.edge_index.shape)
visualize_points(data.pos, edge_index=data.edge_index)
torch.Size([2, 1536])
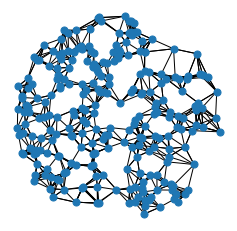
torch.Size([2, 1536])

[6]:
data = dataset[14]
data.edge_index = knn_graph(data.pos, k=6)
print(data.edge_index.shape)
visualize_points(data.pos, edge_index=data.edge_index)
torch.Size([2, 1536])

Here, we import the knn_graph function from torch_cluster and call it by passing in the input points pos and the number of nearest neighbors k. As output, we will receive an edge_index tensor of shape [2, num_edges], which will hold the information of source and target node indices in each column (known as the sparse matrix COO format).
Phase 2: Neighborhood Aggregation¶
The PointNet++layer follows a simple neural message passing scheme defined via
where * \(\mathbf{h}_i^{(\ell)} \in \mathbb{R}^d\) denotes the hidden features of point \(i\) in layer \(\ell\) * \(\mathbf{p}_i \in \mathbb{R}^3\) denotes the position of point \(i\).
We can make use of the `MessagePassing <https://pytorch-geometric.readthedocs.io/en/latest/modules/nn.html>`__ interface to implement this layer. The MessagePassing interface helps us in creating message passing graph neural networks by automatically taking care of message propagation. Here, we only need to define its message function as well as which aggregation scheme to use, e.g., aggr="max" (see
here for the accompanying tutorial):
[7]:
from torch.nn import Sequential, Linear, ReLU
from torch_geometric.nn import MessagePassing
class PointNetLayer(MessagePassing):
def __init__(self, in_channels, out_channels):
# Message passing with "max" aggregation.
super().__init__(aggr='max')
# Initialization of the MLP:
# Here, the number of input features correspond to the hidden node
# dimensionality plus point dimensionality (=3).
self.mlp = Sequential(Linear(in_channels + 3, out_channels),
ReLU(),
Linear(out_channels, out_channels))
def forward(self, h, pos, edge_index):
# Start propagating messages.
return self.propagate(edge_index, h=h, pos=pos)
def message(self, h_j, pos_j, pos_i):
# h_j defines the features of neighboring nodes as shape [num_edges, in_channels]
# pos_j defines the position of neighboring nodes as shape [num_edges, 3]
# pos_i defines the position of central nodes as shape [num_edges, 3]
# Compute spatial relation.
input = pos_j - pos_i
if h_j is not None:
# In the first layer, we may not have any hidden node features,
# so we only combine them in case they are present.
input = torch.cat([h_j, input], dim=-1)
return self.mlp(input) # Apply our final MLP.
As one can see, implementing the PointNet++ layer is quite straightforward in PyTorch Geometric. In the __init__ function, we first define that we want to apply ``max`` aggregation, and afterwards initialize an MLP that takes care of transforming neighboring node features and the spatial relation between source and destination nodes to a (trainable) message.
In the forward function, we can start propagating messages based on edge_index, and pass in everything needed in order to create messages. In the message function, we can now access neighboring and central node information via *_j and *_i, respectively, and return a message for each edge.
Network Architecture¶
We can make use of knn_graph and the PointNetLayer to define our network architecture. Here, we are interested in an architecture that is able to operate on point clouds in a mini-batch fashion. PyTorch Geometric achieves parallelization over mini-batches by creating sparse block diagonal adjacency matrices (defined by edge_index) and concatenating feature matrices in the node dimension (such as pos). For distinguishing examples in a mini-batch, there exists a special vector
named `batch <https://pytorch-geometric.readthedocs.io/en/latest/notes/introduction.html#mini-batches>`__ of shape [num_nodes], which maps each node to its respective graph in the batch:
We need to make use of this batch vector for the knn_graph generation since we do not want to connect nodes from different examples.
With this, our overall PointNet architecture looks as follows:
[8]:
import torch
import torch.nn.functional as F
from torch_cluster import knn_graph
from torch_geometric.nn import global_max_pool
class PointNet(torch.nn.Module):
def __init__(self):
super().__init__()
torch.manual_seed(12345)
self.conv1 = PointNetLayer(3, 32) # 3-d, hidden_size
self.conv2 = PointNetLayer(32, 32)
self.classifier = Linear(32, dataset.num_classes)
def forward(self, pos, batch):
# Compute the kNN graph:
# Here, we need to pass the batch vector to the function call in order
# to prevent creating edges between points of different examples.
# We also add `loop=True` which will add self-loops to the graph in
# order to preserve central point information.
edge_index = knn_graph(pos, k=16, batch=batch, loop=True)
# 3. Start bipartite message passing.
h = self.conv1(h=pos, pos=pos, edge_index=edge_index)
h = h.relu()
h = self.conv2(h=h, pos=pos, edge_index=edge_index)
h = h.relu()
# 4. Global Pooling.
h = global_max_pool(h, batch) # [num_examples, hidden_channels]
# 5. Classifier.
return self.classifier(h)
model = PointNet()
print(model)
PointNet(
(conv1): PointNetLayer()
(conv2): PointNetLayer()
(classifier): Linear(in_features=32, out_features=40, bias=True)
)
Here, we create our network architecture by inheriting from ``torch.nn.Module`` and initialize two ``PointNetLayer`` modules and a final linear classifier (`torch.nn.Linear <https://pytorch.org/docs/stable/generated/torch.nn.Linear.html?highlight=linear#torch.nn.Linear>`__) in its constructor.
In the forward method, we first dynamically generate a 16-nearest neighbor graph based on the position pos of nodes. Based on the resulting graph connectivity, we apply two graph-based convolutional operators and enhance them by ReLU non-linearities. The first operator takes in 3 input features (the positions of nodes) and maps them to 32 output features.
After that, each point holds information about its 2-hop neighborhood, and should already be able to distinguish between simple local shapes.
Next, we apply a global graph readout function, i.e., global_max_pool, which takes the maximum value along the node dimension for each example. Last, we apply a linear classifier to map the remaining 32 features to one of the 40 classes.
Training Procedure¶
We are now ready to write two simple procedures to train and test our model on the training and test dataset, respectively. If you are not new to PyTorch, this scheme should appear familiar to you. Otherwise, the PyTorch docs provide a good introduction on how to train a neural network in PyTorch.
[9]:
# from IPython.display import Javascript # Restrict height of output cell.
# display(Javascript('''google.colab.output.setIframeHeight(0, true, {maxHeight: 300})'''))
from torch_geometric.loader import DataLoader
train_dataset = GeometricShapes(root='data/GeometricShapes', train=True,
transform=SamplePoints(128))
test_dataset = GeometricShapes(root='data/GeometricShapes', train=False,
transform=SamplePoints(128))
train_loader = DataLoader(train_dataset, batch_size=10, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=10)
model = PointNet()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
criterion = torch.nn.CrossEntropyLoss() # Define loss criterion.
def train(model, optimizer, loader):
model.train()
total_loss = 0
for data in loader:
optimizer.zero_grad() # Clear gradients.
logits = model(data.pos, data.batch) # Forward pass.
loss = criterion(logits, data.y) # Loss computation.
loss.backward() # Backward pass.
optimizer.step() # Update model parameters.
total_loss += loss.item() * data.num_graphs
return total_loss / len(train_loader.dataset)
@torch.no_grad()
def test(model, loader):
model.eval()
total_correct = 0
for data in loader:
logits = model(data.pos, data.batch)
pred = logits.argmax(dim=-1)
total_correct += int((pred == data.y).sum())
return total_correct / len(loader.dataset)
for epoch in range(1, 51):
loss = train(model, optimizer, train_loader)
test_acc = test(model, test_loader)
print(f'Epoch: {epoch:02d}, Loss: {loss:.4f}, Test Accuracy: {test_acc:.4f}')
Epoch: 01, Loss: 3.7549, Test Accuracy: 0.0500
Epoch: 02, Loss: 3.7011, Test Accuracy: 0.0250
Epoch: 03, Loss: 3.6830, Test Accuracy: 0.0250
Epoch: 04, Loss: 3.6705, Test Accuracy: 0.0250
Epoch: 05, Loss: 3.6338, Test Accuracy: 0.0250
Epoch: 06, Loss: 3.5937, Test Accuracy: 0.0250
Epoch: 07, Loss: 3.5599, Test Accuracy: 0.0250
Epoch: 08, Loss: 3.4820, Test Accuracy: 0.0500
Epoch: 09, Loss: 3.4096, Test Accuracy: 0.0500
Epoch: 10, Loss: 3.3637, Test Accuracy: 0.0500
Epoch: 11, Loss: 3.2883, Test Accuracy: 0.0750
Epoch: 12, Loss: 3.2181, Test Accuracy: 0.1000
Epoch: 13, Loss: 3.1262, Test Accuracy: 0.1500
Epoch: 14, Loss: 3.0487, Test Accuracy: 0.1750
Epoch: 15, Loss: 2.9215, Test Accuracy: 0.1750
Epoch: 16, Loss: 2.8044, Test Accuracy: 0.2000
Epoch: 17, Loss: 2.6913, Test Accuracy: 0.3500
Epoch: 18, Loss: 2.5293, Test Accuracy: 0.2750
Epoch: 19, Loss: 2.4080, Test Accuracy: 0.4250
Epoch: 20, Loss: 2.1689, Test Accuracy: 0.2750
Epoch: 21, Loss: 2.1438, Test Accuracy: 0.4000
Epoch: 22, Loss: 2.0483, Test Accuracy: 0.3750
Epoch: 23, Loss: 1.8159, Test Accuracy: 0.4250
Epoch: 24, Loss: 1.7395, Test Accuracy: 0.5250
Epoch: 25, Loss: 1.7395, Test Accuracy: 0.4500
Epoch: 26, Loss: 1.5417, Test Accuracy: 0.6000
Epoch: 27, Loss: 1.5056, Test Accuracy: 0.6250
Epoch: 28, Loss: 1.3494, Test Accuracy: 0.6000
Epoch: 29, Loss: 1.4231, Test Accuracy: 0.6500
Epoch: 30, Loss: 1.3399, Test Accuracy: 0.6500
Epoch: 31, Loss: 1.2157, Test Accuracy: 0.7000
Epoch: 32, Loss: 1.2747, Test Accuracy: 0.7000
Epoch: 33, Loss: 1.3160, Test Accuracy: 0.6750
Epoch: 34, Loss: 1.2479, Test Accuracy: 0.7500
Epoch: 35, Loss: 1.3917, Test Accuracy: 0.6250
Epoch: 36, Loss: 1.2487, Test Accuracy: 0.5250
Epoch: 37, Loss: 1.1782, Test Accuracy: 0.5750
Epoch: 38, Loss: 1.2259, Test Accuracy: 0.6750
Epoch: 39, Loss: 1.2377, Test Accuracy: 0.7500
Epoch: 40, Loss: 1.2765, Test Accuracy: 0.7250
Epoch: 41, Loss: 1.0532, Test Accuracy: 0.7000
Epoch: 42, Loss: 1.0478, Test Accuracy: 0.7250
Epoch: 43, Loss: 0.8929, Test Accuracy: 0.7750
Epoch: 44, Loss: 0.8953, Test Accuracy: 0.7750
Epoch: 45, Loss: 0.7948, Test Accuracy: 0.7750
Epoch: 46, Loss: 0.9078, Test Accuracy: 0.7500
Epoch: 47, Loss: 0.8260, Test Accuracy: 0.7500
Epoch: 48, Loss: 0.7181, Test Accuracy: 0.8000
Epoch: 49, Loss: 0.9089, Test Accuracy: 0.7500
Epoch: 50, Loss: 0.7396, Test Accuracy: 0.7750
As one can see, we are able to achieve around 75-80% test accuracy, even when training only on a single example per class (note that we can certainly increase performance by training longer and make use of deeper neural networks).
However, there is one caveat: Since our model takes in node positions as input features, and uses relational Cartesian coordinates for creating messages, i.e. \(\mathbf{p}_j - \mathbf{p}_i\), it does not generalize across different rotations applied to the input point cloud.
Let’s verify this in an example, where we apply random rotations to the test data by composing `RandomRotate <https://pytorch-geometric.readthedocs.io/en/latest/modules/transforms.html#torch_geometric.transforms.RandomRotate>`__ transformations along different axes:
[10]:
from torch_geometric.transforms import Compose, RandomRotate
torch.manual_seed(123)
random_rotate = Compose([
RandomRotate(degrees=180, axis=0),
RandomRotate(degrees=180, axis=1),
RandomRotate(degrees=180, axis=2),
])
dataset = GeometricShapes(root='data/GeometricShapes', transform=random_rotate)
data = dataset[0]
print(data)
visualize_mesh(data.pos, data.face)
data = dataset[4]
print(data)
visualize_mesh(data.pos, data.face)
Data(pos=[32, 3], face=[3, 30], y=[1])
/home/user/anaconda3/envs/gnn/lib/python3.7/site-packages/ipykernel_launcher.py:19: MatplotlibDeprecationWarning: Calling gca() with keyword arguments was deprecated in Matplotlib 3.4. Starting two minor releases later, gca() will take no keyword arguments. The gca() function should only be used to get the current axes, or if no axes exist, create new axes with default keyword arguments. To create a new axes with non-default arguments, use plt.axes() or plt.subplot().

Data(pos=[4, 3], face=[3, 2], y=[1])
[11]:
torch.manual_seed(42)
transform = Compose([
random_rotate,
SamplePoints(num=128),
])
test_dataset = GeometricShapes(root='data/GeometricShapes', train=False,
transform=transform)
test_loader = DataLoader(test_dataset, batch_size=10)
test_acc = test(model, test_loader)
print(f'Test Accuracy: {test_acc:.4f}')
Test Accuracy: 0.2000
What a bummer! By randomly rotating the examples in our test dataset, our model performance decreased to 15%.
The good thing is that there are ways to fix this, so let’s learn about rotation-invariant point cloud processing in the upcoming exercise.
(Optional) Exercises¶
1. Rotation-invariant PointNet Layer¶
The PPFNet is an extension to the PointNet++ architecture that makes it rotation-invariant. More specifically, PPF stands for Point Pair Feature, which describes the relation between two points by a rotation-invariant 4D descriptor
based on 1. the distance between points \(\| \mathbf{p}_j - \mathbf{p}_i \|_2\) and 2. the angles between \(\mathbf{p}_j - \mathbf{p}_i\) and the normal vectors \(\mathbf{n}_i\) and \(\mathbf{n}_j\) of points \(i\) and \(j\), respectively.
Luckily, in addition to the `PointConv <https://pytorch-geometric.readthedocs.io/en/latest/modules/nn.html#torch_geometric.nn.conv.PointConv>`__, PyTorch Geometric also provides an implementation of the PointConv based on the Point Pair Feature descriptor, see `PPFConv <https://pytorch-geometric.readthedocs.io/en/latest/modules/nn.html#torch_geometric.nn.conv.PPFConv>`__. Furthermore, the
`SamplePoints <https://pytorch-geometric.readthedocs.io/en/latest/modules/transforms.html>`__ transformation does also provide normal vectors in data.normal for each sampled point when called via SamplePoints(num_points, include_normals=True).
As an exercise, can you extend the example code below in order to instantiate the PPFConv modules?
Tipp:
The PPFConv expects an MLP as first argument, which is similar to the one created earlier in the PointNetLayer. Note that in PPFConv, we now have a 4D discriptor instead of a 3D one.
[12]:
from torch_geometric.nn import PPFConv
from torch_cluster import fps
# Initialization of the MLP:
# Here, the number of input features correspond to the hidden node
# dimensionality plus point dimensionality (=3).
# self.mlp = Sequential(Linear(in_channels + 3, out_channels),
# ReLU(),
# Linear(out_channels, out_channels))
class PPFNet(torch.nn.Module):
def __init__(self):
super().__init__()
in_channels = 4
out_channels = 32
torch.manual_seed(12345)
# msg = self.local_nn(msg)
mlp1 = Sequential(Linear(4, out_channels),
ReLU(),
Linear(out_channels, out_channels)) # TODO
self.conv1 = PPFConv(local_nn = mlp1) # TODO
mlp2 = Sequential(Linear(out_channels + 4, out_channels),
ReLU(),
Linear(out_channels, out_channels)) # TODO
self.conv2 = PPFConv(local_nn = mlp2) # TODO
self.classifier = Linear(32, dataset.num_classes)
def forward(self, pos, normal, batch):
edge_index = knn_graph(pos, k=16, batch=batch, loop=False)
x = self.conv1(x=None, pos=pos, normal=normal, edge_index=edge_index)
x = x.relu()
x = self.conv2(x=x, pos=pos, normal=normal, edge_index=edge_index)
x = x.relu()
x = global_max_pool(x, batch) # [num_examples, hidden_channels]
return self.classifier(x)
model = PPFNet()
print(model)
PPFNet(
(conv1): PPFConv(local_nn=Sequential(
(0): Linear(in_features=4, out_features=32, bias=True)
(1): ReLU()
(2): Linear(in_features=32, out_features=32, bias=True)
), global_nn=None)
(conv2): PPFConv(local_nn=Sequential(
(0): Linear(in_features=36, out_features=32, bias=True)
(1): ReLU()
(2): Linear(in_features=32, out_features=32, bias=True)
), global_nn=None)
(classifier): Linear(in_features=32, out_features=40, bias=True)
)
[13]:
# from IPython.display import Javascript # Restrict height of output cell.
# display(Javascript('''google.colab.output.setIframeHeight(0, true, {maxHeight: 300})'''))
test_transform = Compose([
random_rotate,
SamplePoints(num=128, include_normals=True),
])
train_dataset = GeometricShapes(root='data/GeometricShapes', train=False,
transform=SamplePoints(128, include_normals=True))
test_dataset = GeometricShapes(root='data/GeometricShapes', train=False,
transform=test_transform)
train_loader = DataLoader(train_dataset, batch_size=10, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=10)
model = PPFNet()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
criterion = torch.nn.CrossEntropyLoss() # Define loss criterion.
def train(model, optimizer, loader):
model.train()
total_loss = 0
for data in loader:
optimizer.zero_grad() # Clear gradients.
logits = model(data.pos, data.normal, data.batch)
loss = criterion(logits, data.y)
loss.backward()
optimizer.step()
total_loss += loss.item() * data.num_graphs
return total_loss / len(train_loader.dataset)
@torch.no_grad()
def test(model, loader):
model.eval()
total_correct = 0
for data in loader:
logits = model(data.pos, data.normal, data.batch)
pred = logits.argmax(dim=-1)
total_correct += int((pred == data.y).sum())
return total_correct / len(loader.dataset)
for epoch in range(1, 101):
loss = train(model, optimizer, train_loader)
test_acc = test(model, test_loader)
print(f'Epoch: {epoch:02d}, Loss: {loss:.4f}, Test Accuracy: {test_acc:.4f}')
Epoch: 01, Loss: 3.7446, Test Accuracy: 0.0250
Epoch: 02, Loss: 3.6986, Test Accuracy: 0.0250
Epoch: 03, Loss: 3.6897, Test Accuracy: 0.0500
Epoch: 04, Loss: 3.6721, Test Accuracy: 0.0500
Epoch: 05, Loss: 3.6497, Test Accuracy: 0.0250
Epoch: 06, Loss: 3.6071, Test Accuracy: 0.0500
Epoch: 07, Loss: 3.5375, Test Accuracy: 0.1000
Epoch: 08, Loss: 3.4830, Test Accuracy: 0.0750
Epoch: 09, Loss: 3.3880, Test Accuracy: 0.0750
Epoch: 10, Loss: 3.2803, Test Accuracy: 0.0750
Epoch: 11, Loss: 3.1950, Test Accuracy: 0.1500
Epoch: 12, Loss: 3.0172, Test Accuracy: 0.1250
Epoch: 13, Loss: 2.8260, Test Accuracy: 0.1500
Epoch: 14, Loss: 2.6123, Test Accuracy: 0.2500
Epoch: 15, Loss: 2.5958, Test Accuracy: 0.3000
Epoch: 16, Loss: 2.3796, Test Accuracy: 0.3000
Epoch: 17, Loss: 2.1558, Test Accuracy: 0.2250
Epoch: 18, Loss: 2.1169, Test Accuracy: 0.3500
Epoch: 19, Loss: 2.0432, Test Accuracy: 0.4000
Epoch: 20, Loss: 1.8356, Test Accuracy: 0.3500
Epoch: 21, Loss: 1.8170, Test Accuracy: 0.4750
Epoch: 22, Loss: 1.6857, Test Accuracy: 0.4000
Epoch: 23, Loss: 1.9516, Test Accuracy: 0.4250
Epoch: 24, Loss: 1.5876, Test Accuracy: 0.3250
Epoch: 25, Loss: 1.8730, Test Accuracy: 0.4500
Epoch: 26, Loss: 1.7069, Test Accuracy: 0.4000
Epoch: 27, Loss: 1.7674, Test Accuracy: 0.4500
Epoch: 28, Loss: 1.7571, Test Accuracy: 0.5000
Epoch: 29, Loss: 1.5569, Test Accuracy: 0.4250
Epoch: 30, Loss: 1.6035, Test Accuracy: 0.4000
Epoch: 31, Loss: 1.8965, Test Accuracy: 0.4750
Epoch: 32, Loss: 1.6370, Test Accuracy: 0.3750
Epoch: 33, Loss: 1.5917, Test Accuracy: 0.4000
Epoch: 34, Loss: 1.6342, Test Accuracy: 0.5250
Epoch: 35, Loss: 1.6760, Test Accuracy: 0.4750
Epoch: 36, Loss: 1.4172, Test Accuracy: 0.5000
Epoch: 37, Loss: 1.3260, Test Accuracy: 0.4750
Epoch: 38, Loss: 1.2936, Test Accuracy: 0.6250
Epoch: 39, Loss: 1.2830, Test Accuracy: 0.5750
Epoch: 40, Loss: 1.3196, Test Accuracy: 0.6000
Epoch: 41, Loss: 1.2341, Test Accuracy: 0.6250
Epoch: 42, Loss: 1.1880, Test Accuracy: 0.6250
Epoch: 43, Loss: 1.2102, Test Accuracy: 0.6250
Epoch: 44, Loss: 1.0993, Test Accuracy: 0.6500
Epoch: 45, Loss: 1.3148, Test Accuracy: 0.5750
Epoch: 46, Loss: 1.1733, Test Accuracy: 0.6750
Epoch: 47, Loss: 1.2139, Test Accuracy: 0.5500
Epoch: 48, Loss: 1.3851, Test Accuracy: 0.5750
Epoch: 49, Loss: 1.3868, Test Accuracy: 0.5500
Epoch: 50, Loss: 1.4406, Test Accuracy: 0.5750
Epoch: 51, Loss: 1.2963, Test Accuracy: 0.5250
Epoch: 52, Loss: 1.3279, Test Accuracy: 0.6000
Epoch: 53, Loss: 1.2319, Test Accuracy: 0.7000
Epoch: 54, Loss: 1.1879, Test Accuracy: 0.6250
Epoch: 55, Loss: 1.1360, Test Accuracy: 0.6250
Epoch: 56, Loss: 1.0774, Test Accuracy: 0.6250
Epoch: 57, Loss: 1.0337, Test Accuracy: 0.6250
Epoch: 58, Loss: 1.0178, Test Accuracy: 0.6000
Epoch: 59, Loss: 1.0764, Test Accuracy: 0.7750
Epoch: 60, Loss: 0.9314, Test Accuracy: 0.6000
Epoch: 61, Loss: 1.0321, Test Accuracy: 0.7500
Epoch: 62, Loss: 0.9245, Test Accuracy: 0.6500
Epoch: 63, Loss: 1.1455, Test Accuracy: 0.7500
Epoch: 64, Loss: 0.8144, Test Accuracy: 0.6750
Epoch: 65, Loss: 0.9841, Test Accuracy: 0.6500
Epoch: 66, Loss: 0.8748, Test Accuracy: 0.6250
Epoch: 67, Loss: 0.9384, Test Accuracy: 0.6750
Epoch: 68, Loss: 0.9578, Test Accuracy: 0.5750
Epoch: 69, Loss: 1.0938, Test Accuracy: 0.5750
Epoch: 70, Loss: 0.9153, Test Accuracy: 0.7250
Epoch: 71, Loss: 0.9288, Test Accuracy: 0.7000
Epoch: 72, Loss: 0.9709, Test Accuracy: 0.6750
Epoch: 73, Loss: 0.8939, Test Accuracy: 0.6250
Epoch: 74, Loss: 0.8348, Test Accuracy: 0.6000
Epoch: 75, Loss: 0.8355, Test Accuracy: 0.7000
Epoch: 76, Loss: 0.8753, Test Accuracy: 0.6500
Epoch: 77, Loss: 0.7447, Test Accuracy: 0.6750
Epoch: 78, Loss: 0.8518, Test Accuracy: 0.6750
Epoch: 79, Loss: 0.8865, Test Accuracy: 0.6750
Epoch: 80, Loss: 0.8418, Test Accuracy: 0.7250
Epoch: 81, Loss: 0.7932, Test Accuracy: 0.7000
Epoch: 82, Loss: 0.8698, Test Accuracy: 0.6750
Epoch: 83, Loss: 0.8433, Test Accuracy: 0.7250
Epoch: 84, Loss: 0.7910, Test Accuracy: 0.7500
Epoch: 85, Loss: 0.7013, Test Accuracy: 0.7500
Epoch: 86, Loss: 1.0273, Test Accuracy: 0.6500
Epoch: 87, Loss: 0.8865, Test Accuracy: 0.7000
Epoch: 88, Loss: 0.9813, Test Accuracy: 0.6750
Epoch: 89, Loss: 1.2420, Test Accuracy: 0.5750
Epoch: 90, Loss: 1.0185, Test Accuracy: 0.5000
Epoch: 91, Loss: 1.1347, Test Accuracy: 0.5000
Epoch: 92, Loss: 0.9145, Test Accuracy: 0.5500
Epoch: 93, Loss: 0.8735, Test Accuracy: 0.7000
Epoch: 94, Loss: 0.8784, Test Accuracy: 0.7250
Epoch: 95, Loss: 1.0736, Test Accuracy: 0.7000
Epoch: 96, Loss: 0.8358, Test Accuracy: 0.6750
Epoch: 97, Loss: 0.7955, Test Accuracy: 0.5750
Epoch: 98, Loss: 0.8413, Test Accuracy: 0.7750
Epoch: 99, Loss: 0.7425, Test Accuracy: 0.7250
Epoch: 100, Loss: 0.9222, Test Accuracy: 0.6750
2. Downsampling Phase via Farthest Point Sampling¶
So far, we haven’t made use of downsampling/pooling the point cloud. In the PointNet++ architecture, downsampling of a point clouds is achieved via the Farthest Point Sampling (FPS) procedure, which, in return, allows the network to extract more and more global features. Given an input point set \(\{ \mathbf{p}_1, \ldots \mathbf{p}_n \}\), FPS iteratively selects a subset of points such that the sampled points are furthest apart. Specifically, compared with random sampling, this procedure is known to have better coverage of the entire point set.
Luckily, PyTorch Geometric provides a ready-to-use implementation of `fps <https://pytorch-geometric.readthedocs.io/en/latest/modules/nn.html#torch_geometric.nn.pool.fps>`__, which takes in the position of nodes and a sampling ratio, and returns the indices of nodes that have been sampled:
[14]:
from torch_cluster import fps
dataset = GeometricShapes(root='data/GeometricShapes', transform=SamplePoints(128))
data = dataset[0]
index = fps(data.pos, ratio=0.25)
visualize_points(data.pos)
visualize_points(data.pos, index=index)


With this, can you modify the PPFNet model to include a farthest point sampling step (ratio=0.5) in between the two convolution operators?
Tipp:
For fps, you also need to pass in the batch vector, so that points in different examples are sampled independently from each other:
index = fps(pos, batch, ratio=0.5)
You can now pool the points, their normals, the features and the batch vector via:
pos = pos[index]
normal = normal[index]
h = h[index]
batch = batch[index]
This will just keep the points sampled by fps.
Note that you also need to create a new \(k\)-NN graph after applying the pooling operation.
[15]:
class PPFNet_fps(torch.nn.Module):
def __init__(self):
super().__init__()
in_channels = 4
out_channels = 32
torch.manual_seed(12345)
# msg = self.local_nn(msg)
mlp1 = Sequential(Linear(4, out_channels),
ReLU(),
Linear(out_channels, out_channels)) # TODO
self.conv1 = PPFConv(local_nn = mlp1) # TODO
mlp2 = Sequential(Linear(out_channels + 4, out_channels),
ReLU(),
Linear(out_channels, out_channels)) # TODO
self.conv2 = PPFConv(local_nn = mlp2) # TODO
self.classifier = Linear(32, dataset.num_classes)
def forward(self, pos, normal, batch):
# the first layer
edge_index = knn_graph(pos, k=16, batch=batch, loop=False)
x = self.conv1(x=None, pos=pos, normal=normal, edge_index=edge_index)
x = x.relu()
# Farthest Point Sampling
index = fps(pos, batch, ratio=0.5)
pos = pos[index]
normal = normal[index]
x = x[index]
batch = batch[index]
# the second layer
edge_index = knn_graph(pos, k=16, batch=batch, loop=False)
x = self.conv2(x=x, pos=pos, normal=normal, edge_index=edge_index)
x = x.relu()
x = global_max_pool(x, batch) # [num_examples, hidden_channels]
return self.classifier(x)
model = PPFNet_fps()
print(model)
PPFNet_fps(
(conv1): PPFConv(local_nn=Sequential(
(0): Linear(in_features=4, out_features=32, bias=True)
(1): ReLU()
(2): Linear(in_features=32, out_features=32, bias=True)
), global_nn=None)
(conv2): PPFConv(local_nn=Sequential(
(0): Linear(in_features=36, out_features=32, bias=True)
(1): ReLU()
(2): Linear(in_features=32, out_features=32, bias=True)
), global_nn=None)
(classifier): Linear(in_features=32, out_features=40, bias=True)
)
[16]:
# from IPython.display import Javascript # Restrict height of output cell.
# display(Javascript('''google.colab.output.setIframeHeight(0, true, {maxHeight: 300})'''))
test_transform = Compose([
random_rotate,
SamplePoints(num=128, include_normals=True),
])
train_dataset = GeometricShapes(root='data/GeometricShapes', train=False,
transform=SamplePoints(128, include_normals=True))
test_dataset = GeometricShapes(root='data/GeometricShapes', train=False,
transform=test_transform)
train_loader = DataLoader(train_dataset, batch_size=10, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=10)
model = PPFNet_fps()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
criterion = torch.nn.CrossEntropyLoss() # Define loss criterion.
def train(model, optimizer, loader):
model.train()
total_loss = 0
for data in loader:
optimizer.zero_grad() # Clear gradients.
logits = model(data.pos, data.normal, data.batch)
loss = criterion(logits, data.y)
loss.backward()
optimizer.step()
total_loss += loss.item() * data.num_graphs
return total_loss / len(train_loader.dataset)
@torch.no_grad()
def test(model, loader):
model.eval()
total_correct = 0
for data in loader:
logits = model(data.pos, data.normal, data.batch)
pred = logits.argmax(dim=-1)
total_correct += int((pred == data.y).sum())
return total_correct / len(loader.dataset)
for epoch in range(1, 101):
loss = train(model, optimizer, train_loader)
test_acc = test(model, test_loader)
print(f'Epoch: {epoch:02d}, Loss: {loss:.4f}, Test Accuracy: {test_acc:.4f}')
Epoch: 01, Loss: 3.7451, Test Accuracy: 0.0250
Epoch: 02, Loss: 3.6966, Test Accuracy: 0.0250
Epoch: 03, Loss: 3.6781, Test Accuracy: 0.0500
Epoch: 04, Loss: 3.6492, Test Accuracy: 0.0750
Epoch: 05, Loss: 3.6009, Test Accuracy: 0.0500
Epoch: 06, Loss: 3.5318, Test Accuracy: 0.0500
Epoch: 07, Loss: 3.4322, Test Accuracy: 0.0500
Epoch: 08, Loss: 3.3297, Test Accuracy: 0.0500
Epoch: 09, Loss: 3.1831, Test Accuracy: 0.1250
Epoch: 10, Loss: 3.0835, Test Accuracy: 0.1250
Epoch: 11, Loss: 2.9942, Test Accuracy: 0.1250
Epoch: 12, Loss: 2.8637, Test Accuracy: 0.2250
Epoch: 13, Loss: 2.6610, Test Accuracy: 0.2750
Epoch: 14, Loss: 2.5857, Test Accuracy: 0.2000
Epoch: 15, Loss: 2.4421, Test Accuracy: 0.3000
Epoch: 16, Loss: 2.2699, Test Accuracy: 0.2750
Epoch: 17, Loss: 2.0972, Test Accuracy: 0.3750
Epoch: 18, Loss: 1.9800, Test Accuracy: 0.4750
Epoch: 19, Loss: 1.8850, Test Accuracy: 0.4750
Epoch: 20, Loss: 1.7047, Test Accuracy: 0.4500
Epoch: 21, Loss: 1.7520, Test Accuracy: 0.4000
Epoch: 22, Loss: 1.6793, Test Accuracy: 0.4250
Epoch: 23, Loss: 1.4900, Test Accuracy: 0.5750
Epoch: 24, Loss: 2.0241, Test Accuracy: 0.6000
Epoch: 25, Loss: 1.6157, Test Accuracy: 0.5000
Epoch: 26, Loss: 1.3760, Test Accuracy: 0.4750
Epoch: 27, Loss: 1.4919, Test Accuracy: 0.4750
Epoch: 28, Loss: 1.5318, Test Accuracy: 0.4750
Epoch: 29, Loss: 1.4839, Test Accuracy: 0.5250
Epoch: 30, Loss: 1.3582, Test Accuracy: 0.5250
Epoch: 31, Loss: 1.4813, Test Accuracy: 0.4000
Epoch: 32, Loss: 1.4896, Test Accuracy: 0.3750
Epoch: 33, Loss: 1.4826, Test Accuracy: 0.5000
Epoch: 34, Loss: 1.5252, Test Accuracy: 0.4250
Epoch: 35, Loss: 1.5797, Test Accuracy: 0.6500
Epoch: 36, Loss: 1.3004, Test Accuracy: 0.6250
Epoch: 37, Loss: 1.1583, Test Accuracy: 0.4500
Epoch: 38, Loss: 1.2926, Test Accuracy: 0.5250
Epoch: 39, Loss: 1.3815, Test Accuracy: 0.6750
Epoch: 40, Loss: 1.0436, Test Accuracy: 0.6250
Epoch: 41, Loss: 1.1093, Test Accuracy: 0.6000
Epoch: 42, Loss: 1.1140, Test Accuracy: 0.7500
Epoch: 43, Loss: 0.9859, Test Accuracy: 0.7000
Epoch: 44, Loss: 1.0656, Test Accuracy: 0.7000
Epoch: 45, Loss: 1.0423, Test Accuracy: 0.6500
Epoch: 46, Loss: 1.0862, Test Accuracy: 0.6750
Epoch: 47, Loss: 1.1979, Test Accuracy: 0.6250
Epoch: 48, Loss: 1.0980, Test Accuracy: 0.5750
Epoch: 49, Loss: 1.3192, Test Accuracy: 0.4750
Epoch: 50, Loss: 1.3970, Test Accuracy: 0.6000
Epoch: 51, Loss: 1.1179, Test Accuracy: 0.5500
Epoch: 52, Loss: 1.1962, Test Accuracy: 0.5750
Epoch: 53, Loss: 1.1846, Test Accuracy: 0.6500
Epoch: 54, Loss: 1.2515, Test Accuracy: 0.6250
Epoch: 55, Loss: 1.0778, Test Accuracy: 0.5500
Epoch: 56, Loss: 1.1174, Test Accuracy: 0.6250
Epoch: 57, Loss: 1.0691, Test Accuracy: 0.6250
Epoch: 58, Loss: 1.3362, Test Accuracy: 0.6250
Epoch: 59, Loss: 1.1651, Test Accuracy: 0.6250
Epoch: 60, Loss: 1.0280, Test Accuracy: 0.6500
Epoch: 61, Loss: 0.9167, Test Accuracy: 0.7000
Epoch: 62, Loss: 0.9568, Test Accuracy: 0.5750
Epoch: 63, Loss: 1.0083, Test Accuracy: 0.6500
Epoch: 64, Loss: 0.9117, Test Accuracy: 0.6500
Epoch: 65, Loss: 0.8871, Test Accuracy: 0.6500
Epoch: 66, Loss: 0.7865, Test Accuracy: 0.7000
Epoch: 67, Loss: 0.8124, Test Accuracy: 0.6250
Epoch: 68, Loss: 0.7994, Test Accuracy: 0.7000
Epoch: 69, Loss: 1.0941, Test Accuracy: 0.7250
Epoch: 70, Loss: 0.8307, Test Accuracy: 0.6500
Epoch: 71, Loss: 0.9347, Test Accuracy: 0.6500
Epoch: 72, Loss: 0.8867, Test Accuracy: 0.6750
Epoch: 73, Loss: 0.8697, Test Accuracy: 0.8000
Epoch: 74, Loss: 0.8405, Test Accuracy: 0.6500
Epoch: 75, Loss: 0.8465, Test Accuracy: 0.7000
Epoch: 76, Loss: 1.0251, Test Accuracy: 0.7000
Epoch: 77, Loss: 0.9349, Test Accuracy: 0.7500
Epoch: 78, Loss: 0.7846, Test Accuracy: 0.7000
Epoch: 79, Loss: 0.9056, Test Accuracy: 0.7250
Epoch: 80, Loss: 0.8868, Test Accuracy: 0.7000
Epoch: 81, Loss: 1.1646, Test Accuracy: 0.7000
Epoch: 82, Loss: 1.1432, Test Accuracy: 0.7000
Epoch: 83, Loss: 0.9100, Test Accuracy: 0.6250
Epoch: 84, Loss: 0.9487, Test Accuracy: 0.6750
Epoch: 85, Loss: 1.1216, Test Accuracy: 0.6500
Epoch: 86, Loss: 0.9195, Test Accuracy: 0.6250
Epoch: 87, Loss: 0.7989, Test Accuracy: 0.6750
Epoch: 88, Loss: 0.6794, Test Accuracy: 0.7000
Epoch: 89, Loss: 0.8679, Test Accuracy: 0.6500
Epoch: 90, Loss: 0.9621, Test Accuracy: 0.7750
Epoch: 91, Loss: 0.8067, Test Accuracy: 0.6000
Epoch: 92, Loss: 0.7971, Test Accuracy: 0.7750
Epoch: 93, Loss: 0.8170, Test Accuracy: 0.7750
Epoch: 94, Loss: 0.8543, Test Accuracy: 0.7250
Epoch: 95, Loss: 0.8847, Test Accuracy: 0.6750
Epoch: 96, Loss: 0.7491, Test Accuracy: 0.6500
Epoch: 97, Loss: 1.0006, Test Accuracy: 0.5500
Epoch: 98, Loss: 0.9668, Test Accuracy: 0.5750
Epoch: 99, Loss: 1.4502, Test Accuracy: 0.6250
Epoch: 100, Loss: 1.0589, Test Accuracy: 0.6500
[ ]: